
Introduzione
Lo studio in oggetto ha generato una notevole eco mediatica nell’alimentare la tesi secondo la quale l’uso di modelli linguistici di grandi dimensioni (LLM) come ChatGPT possa avere un impatto negativo sulle capacità cognitive umane. Una prima considerazione preliminare riguarda la sede di pubblicazione: arXiv è una piattaforma pre-print, che consente la diffusione di lavori non ancora sottoposti a revisione paritaria (peer review). Pertanto, sebbene lo studio sia pubblico e citabile, esso non può essere considerato validato dalla comunità scientifica fintanto che non sarà sottoposto a scrutinio formale.
Struttura e contenuti dello studio
Il lavoro si apre con un’ampia introduzione: delle 21 pagine iniziali, al netto di indice e sintesi dei risultati, gran parte è dedicata a inquadrare il tema generale dei LLM, della produzione di testi (essays) e delle performance cognitive connesse ai processi di apprendimento. Tali sezioni, pur interessanti per delineare lo sfondo teorico, non apportano elementi di rilievo metodologico.
Materiali e metodi
Dal punto di vista sperimentale, lo studio ha coinvolto un campione di 60 partecipanti di età compresa tra 18 e 35 anni reclutati presso università dell’area di Boston. Si tratta, pertanto, di un campione di dimensioni contenute e caratterizzato da una ristretta fascia di età. Tale circostanza solleva due osservazioni:
1. La scarsa stratificazione interna, che accorpa soggetti di età neurofisiologicamente distinta (un diciottenne e un trentacinquenne presentano differenze significative in termini di plasticità sinaptica);
2. L’eccessiva selettività socio-culturale, poiché il reclutamento in uno dei contesti accademici più qualificati al mondo introduce un rilevante selection bias. Tale limite, peraltro, è esplicitamente riconosciuto dagli stessi autori.
Il compito assegnato ai partecipanti consisteva nella redazione di un breve saggio (essay). I soggetti sono stati randomizzati in tre gruppi sperimentali:
- Gruppo 1: utilizzo esclusivo di ChatGPT;
- Gruppo 2: utilizzo di motori di ricerca tradizionali (es. Google), con disattivazione di strumenti AI-based come Gemini;
- Gruppo 3: nessun supporto esterno, solo le proprie capacità cognitive.
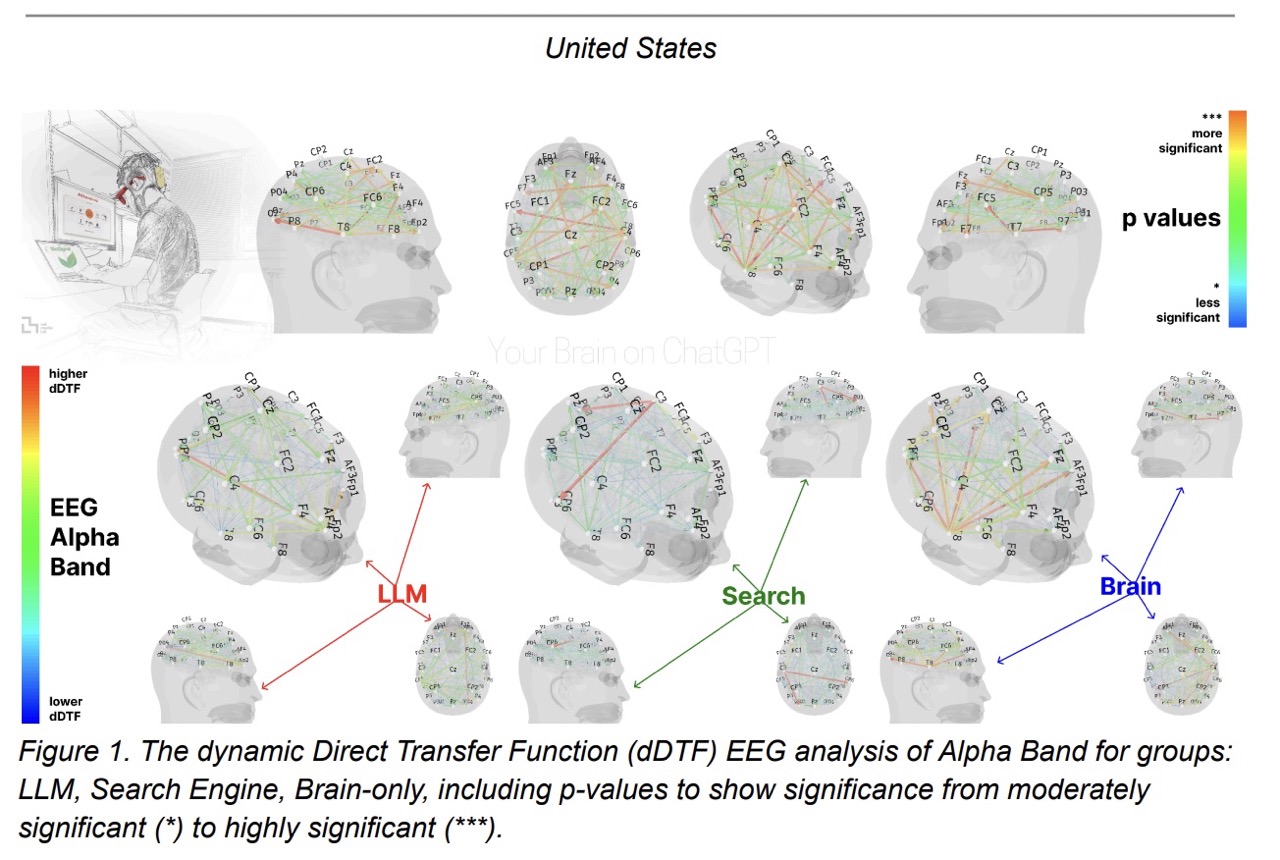
Il disegno sperimentale prevedeva tre sessioni di scrittura su temi diversi, con una quarta sessione facoltativa. L’attività è stata condotta in parallelo a una registrazione elettroencefalografica (EEG). Al termine di ciascun task, i partecipanti hanno compilato un questionario volto a raccogliere informazioni su criteri di scelta dell’argomento, struttura del testo, percezione soggettiva del compito e modalità di utilizzo dello strumento assegnato.
Infine, la valutazione dei testi prodotti è stata condotta tramite Natural Language Processing (NLP), analizzando parametri quali fluidità, originalità e variabilità stilistica.
Criticità metodologiche
Tra i limiti minori si segnalano:
- l’esiguo numero di soggetti che hanno completato la quarta sessione (solo 18 partecipanti, statisticamente irrilevanti);
- il tempo estremamente ridotto assegnato per la scrittura (20 minuti);
- l’assenza di informazioni dettagliate sul momento della giornata in cui si è svolto il compito, sul distanziamento tra le sessioni e sul controllo di variabili confondenti quali stanchezza, livelli ormonali e capacità di concentrazione.
Ben più rilevanti sono i limiti legati all’uso dell’EEG, tecnologia che, seppur diffusa negli studi di neuroscienze cognitive, presenta significative restrizioni nella misurazione di processi complessi come la brain connectivity. L’EEG registra le correnti elettriche generate da vasti gruppi neuronali (da decine di migliaia a milioni di neuroni), ma non è in grado di restituire informazioni di dettaglio sulla connettività sinaptica né di distinguere in modo puntuale aree corticali di piccola scala. Va inoltre sottolineato come termini quali brain connectivity e network coupling, utilizzati dagli autori, possano generare interpretazioni fuorvianti circa la portata del segnale effettivamente misurabile.
Un ulteriore elemento critico è costituito dall’assenza di blinding: i partecipanti erano consapevoli del gruppo di appartenenza, la qual cosa ha esposto così lo studio a possibili bias di aspettativa. Mancava, inoltre, una valutazione preliminare delle competenze cognitive individuali, che avrebbe consentito di normalizzare i risultati rispetto alle abilità pregresse.
Risultati principali
I principali risultati riportati possono essere così riassunti:
- I partecipanti che hanno utilizzato ChatGPT hanno ottenuto i punteggi peggiori nei questionari post-task, in particolare in relazione alla capacità di ricordare il contenuto prodotto e alla soddisfazione soggettiva (satisfaction);
- L’EEG ha evidenziato, per il gruppo ChatGPT, una ridotta coordinazione temporale delle correnti elettriche e una diminuzione delle frequenze associate all’impegno cognitivo;
- L’analisi NLP ha indicato una maggiore varietà stilistica e contenutistica nei testi redatti esclusivamente con risorse cognitive proprie, mentre i testi supportati da LLM risultavano più stereotipati, impersonali e poveri di insight.
Discussione
I dati raccolti suggeriscono una possibile correlazione tra l’uso di LLM e una minore attivazione di specifici pattern di attività cerebrale, nonché una produzione testuale meno originale. Tuttavia, come noto, correlazione non implica causalità. È altresì plausibile ipotizzare che la capacità di utilizzare ChatGPT in modo efficace richieda competenze distinte rispetto a quelle attivate nella composizione di un saggio ex novo, coinvolgendo circuiti corticali differenti e determinando pattern EEG diversi.
Inoltre, l’entità limitata del campione, le criticità metodologiche e l’assenza di revisione paritaria rendono prematuro inferire conclusioni generalizzabili. Gli stessi autori, con apprezzabile trasparenza, segnalano i limiti del lavoro.
Conclusioni
Lo studio rappresenta un contributo preliminare interessante e genera un’ipotesi di lavoro che merita di essere verificata mediante ulteriori ricerche, condotte con campioni più ampi, disegni sperimentali più articolati e metodologie di indagine complementari (inclusa la risonanza magnetica funzionale, non priva a sua volta di limiti).
La risonanza mediatica di questo pre-print appare sproporzionata rispetto al livello di evidenza scientifica offerto e segnala ancora una volta la necessità di un approccio critico alla divulgazione dei risultati non peer-reviewed.
Infine, a titolo aneddotico, va notato che l’autore di questo articolo ha sottoposto la propria analisi a ChatGPT stessa, che ha riconosciuto gran parte delle criticità qui discusse, senza al contempo rilevare conflitti di interesse nella propria autovalutazione.







